前面是正常步骤,环境变量安装需要的Hadoop版本和Java版本
这里只说下小细节:
hadoop-env.sh和yarn-env.sh里面需要添加export JAVA_HOME=
切记配置好hosts映射和免密码登录(main>worker worker>main都需要正常,确保每个节点都能无密码登录到其他节点)
另外:在Hadoop 3.X后,50070端口变成了9870端口,请注意
固定每个节点IP,请看我另外一篇文章:点我跳转
可供参考的配置文件:
core-site.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://main:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop-3.2.3/hadoop-cache/tmp</value>
</property>
<property>
<name>dfs.namenode.http-address</name>
<value>main:9870</value>
</property>
</configuration>
|
hdfs-site.xml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop-3.2.3/hadoop-cache/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop-3.2.3/hadoop-cache/dfs/data</value>
</property>
</configuration>
|
mapred-site.xml:
1
2
3
4
5
6
|
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
|
yarn-site.xml:
1
2
3
4
5
6
7
8
9
10
|
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>main</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
|
当配置全部修改完成后,需要将main节点的配置下发到worker节点
1
2
|
scp /opt/hadoop-3.2.3/etc/hadoop/* worker1:/opt/hadoop-3.2.3/etc/hadoop/
scp /opt/hadoop-3.2.3/etc/hadoop/* worker2:/opt/hadoop-3.2.3/etc/hadoop/
|
一切准备就绪后,进行格式化节点(仅在第一次启动之前需要操作)
另外附上几个可能用的到的命令:
1
|
$HADOOP_HOME/sbin/start-all.sh #一键启动所有节点
|
1
|
$HADOOP_HOME/sbin/stop-all.sh #一键关闭所有节点
|
1
|
hdfs dfsadmin -report #hadoop状态检测
|
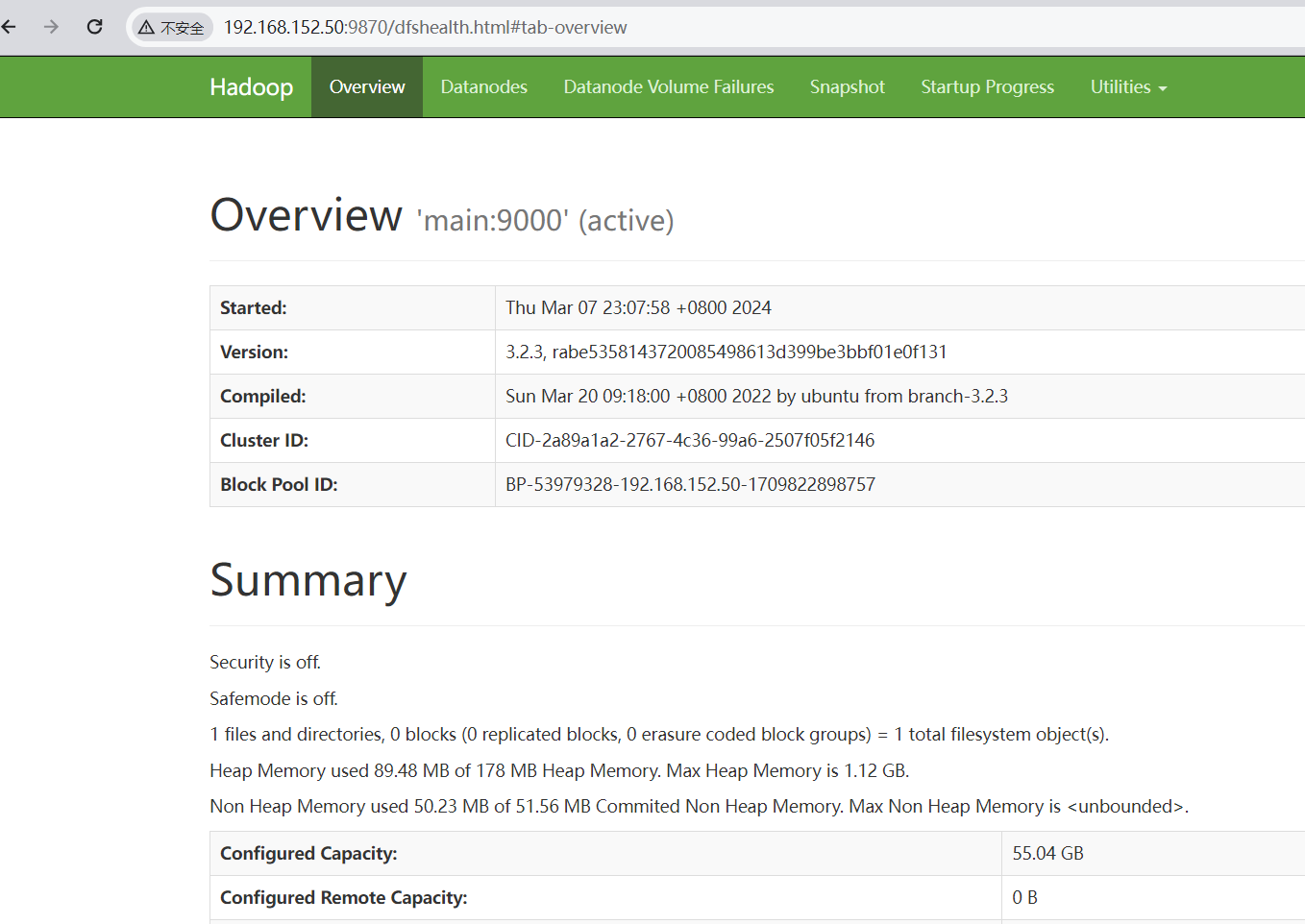
按上面的配置,当启动完成后,你应当能在 main:9870 看到如下界面: